“I’d like to track a history of participants on regular Teams meeting, can I somehow get information from the attendance report with Power Automate?”
MS Teams has a nice feature that’ll allow the meeting organiser to download an attendance report. You’ll get a .csv file with information about the meeting and the participants. There’s a full name, join and leave time, duration, email address, and role for each of them. The .csv report is easy to read if you open it in Excel as Excel will format it in an easy to read way. But without Excel it’s not so pretty. And if you want to process it automatically, you’ll need to process the original file in its format.
This post will describe how to parse the .csv file so you can process the participants data, e.g. to track the attendance in a SharePoint list.
Store the file, trigger the flow
Power Automate doesn’t have an action that would download the report automatically, the first step will be always manual. Download the file and upload it to a specific location, e.g. SharePoint document library. You’ll have to manually download and upload the file after each meeting.
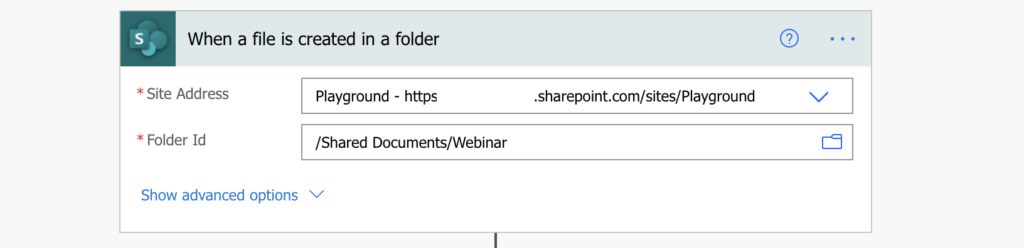
Use that folder in a trigger ‘When a file is created in folder’.
When you do a test run using only the trigger and a ‘Compose’ action (as you need at least 2 actions in a flow), you’ll see the actual format of the .csv file. It’s divided in three sections: Summary, Participants, and In-Meeting activities, e.g.
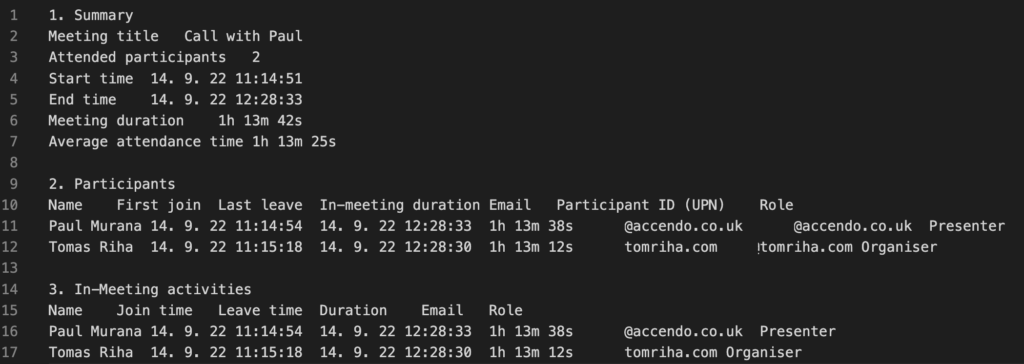
That’s what you get, all the meeting data that you can extract.
Note: you can now replace most of the steps in this flow by a single request to ChatGPT.
Extract only the Participants section
The first step is to skip all the meeting information that’s not relevant as you’re interested only in the participants. Since the sections are separated by an extra row, it means that there’re two new line characters between them. Use the split(…) expression to split the data into the sections.
split(triggerOutputs()?['body'],decodeUriComponent('%0A%0A'))
You’re interested only in the Participants – second section, add index [1] at the end.
split(triggerOutputs()?['body'],decodeUriComponent('%0A%0A'))[1]
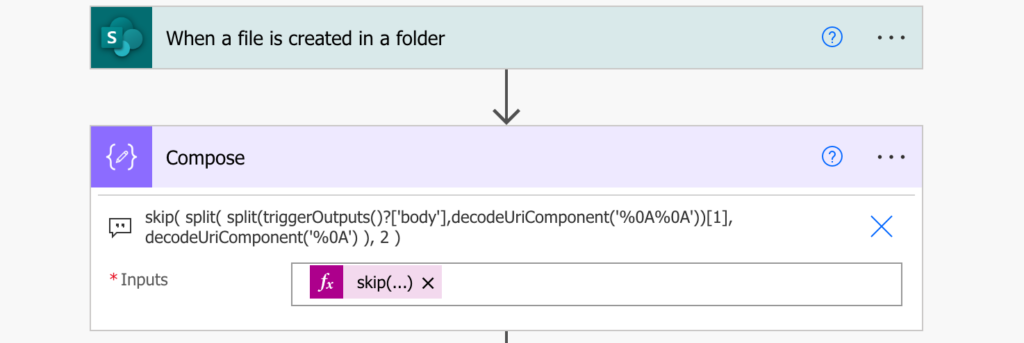
It still contains the section name and the header, but you can remove them by another split(…). Split the rows by a new line (this time only 1), and skip the first two of them. The result will be the rows with the user information.
skip(
split(
split(triggerOutputs()?['body'],decodeUriComponent('%0A%0A'))[1],
decodeUriComponent('%0A')
),
2
)

Extract the user information
Since it’s an array, you’ll have to loop through it in ‘Apply to each’ to process the rows one by one.
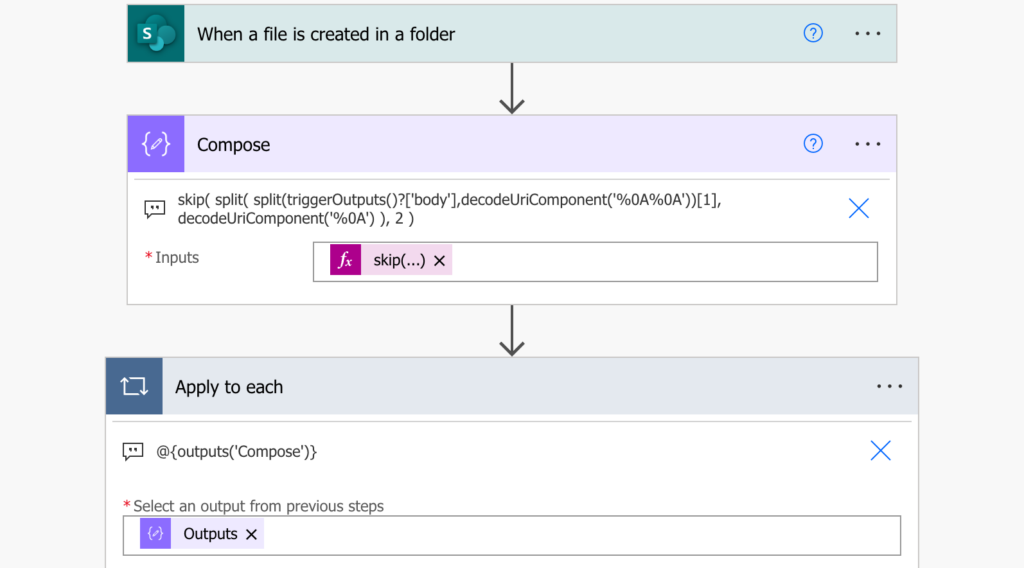
In that loop you’ll extract all the pieces of information about each user. As you could see above, the pieces of information are separated by the tab (shown as \t) character.
Don’t try to split(…) the rows by the ‘\t’, it won’t work. You must encode the tab character in the same way you encode the new line character. The uri value for tab is %09.
decodeUriComponent('%09')Using an index to access the specific part of such split(…) you can directly access all the pieces of information and use it. The ‘Compose’ example below could be as well ‘Create item’, ‘Condition’, or any other flow action processing the attendees.
split(item(),decodeUriComponent('%09'))[0] ...Name
split(item(),decodeUriComponent('%09'))[1] ...First join
split(item(),decodeUriComponent('%09'))[2] ...Last leave
split(item(),decodeUriComponent('%09'))[3] ...In-Meeting duration
split(item(),decodeUriComponent('%09'))[4] ...Email
split(item(),decodeUriComponent('%09'))[5] ...Participant ID (UPN)
split(item(),decodeUriComponent('%09'))[6] ...Role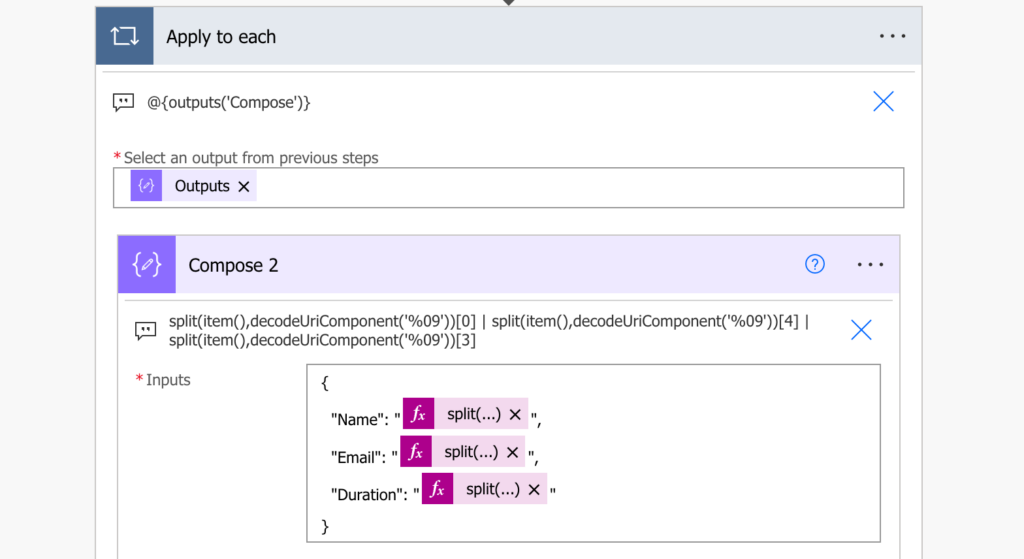
Get the duration in minutes
All the date columns: First join, Last leave, and In-Meeting duration might differ based on your local settings. In this example we’ll process the In-Meeting duration in english locale and covert it into minutes.
Note: this section is optional, if you’re fine with the In-Meeting duration format you can keep it as it is.
Process the hours
Start from directly accessing the In-Meeting duration value, that’ll give you the duration in format ‘-h –m –s’, ‘–m –s’, or just ‘–s’.
split(item(),decodeUriComponent('%09'))[3]
To get the number of minutes, split(…) it once more. Split it by ‘h ‘ and take only the 1st part, the number of hours on index 0.
split(split(item(),decodeUriComponent('%09'))[3],'h ')[0]
The number of hours should be multiplied by 60 to get number of minutes with the mul(…) expression. But to do that, you must also convert the number of hours into integer with the int(…) expression. The result will be the number of hours in minutes.
mul(int(split(split(item(),decodeUriComponent('%09'))[3],'h ')[0]),60)Process the minutes
Now it’s time to process also the minutes. Start from the same split(…) as when processing hours, but this time take the second part of the split, the minutes and seconds on index 1.
split(split(item(),decodeUriComponent('%09'))[3],'h ')[1]The result will be ‘–m –s’. Remove the ‘m’ with the replace(…) expression to keep only the number of minutes.

Follow with another split, this time by the ‘m ‘ to isolate only the minutes on index 0.
split(split(split(item(),decodeUriComponent('%09'))[3],'h ')[1], 'm ')[0]
And convert them into an integer.
int(split(split(split(item(),decodeUriComponent('%09'))[3],'h ')[1], 'm ')[0])Process the seconds
The seconds can be then accessed using a similar expression as for the minutes. Instead of the part before the ‘m ‘ take the part after while replacing the ‘s’ character.
replace(split(split(split(item(),decodeUriComponent('%09'))[3],'h ')[1], 'm ')[1],'s','')Or you can just add the number 1 since we’re converting the attendance time to minutes.
Calculate the whole duration in minutes
The more complicated part comes when you try to put it all together. The problem is that the duration in the Teams attendance report doesn’t have a fixed format, therefore, you must expect anything in the Power Automate flow. It can have various combinations of -h, –m, and –s, and all of them must be included in the final expression.
Does it contain all, -h, –m, –s? Combine all the expressions above. Is one of them missing? Use only part of the expressions and base them on other letters. For example, if there’s no ‘h’, you can’t base any of the expressions on the ‘h’ character.
The final expression will then look as shared by Tyler in the comments:
if(contains(split(item(),decodeUriComponent('%09'))[3], 'h'),
if(contains(split(item(),decodeUriComponent('%09'))[3], 's'),
if(contains(split(item(),decodeUriComponent('%09'))[3], 'm'),
add(1, add(mul(int(split(split(item(),decodeUriComponent('%09'))[3],'h ')[0]),60), int(split(split(split(item(),decodeUriComponent('%09'))[3],'h ')[1],'m ')[0]))),
add(1, mul(int(split(split(item(),decodeUriComponent('%09'))[3],'h')[0]),60))
),
if(contains(split(item(),decodeUriComponent('%09'))[3], 'm'),
add(mul(int(split(split(item(),decodeUriComponent('%09'))[3],'h ')[0]),60),int(replace(split(split(item(),decodeUriComponent('%09'))[3],'h ')[1],'m',''))),
mul(int(split(split(item(),decodeUriComponent('%09'))[3],'h ')[0]),60)
)
),
if(contains(split(item(),decodeUriComponent('%09'))[3], 's'),
if(contains(split(item(),decodeUriComponent('%09'))[3], 'm'),
add(1, int(split(split(item(),decodeUriComponent('%09'))[3],'m')[0])),
1
),
int(split(split(item(),decodeUriComponent('%09'))[3],'m')[0])
)
)
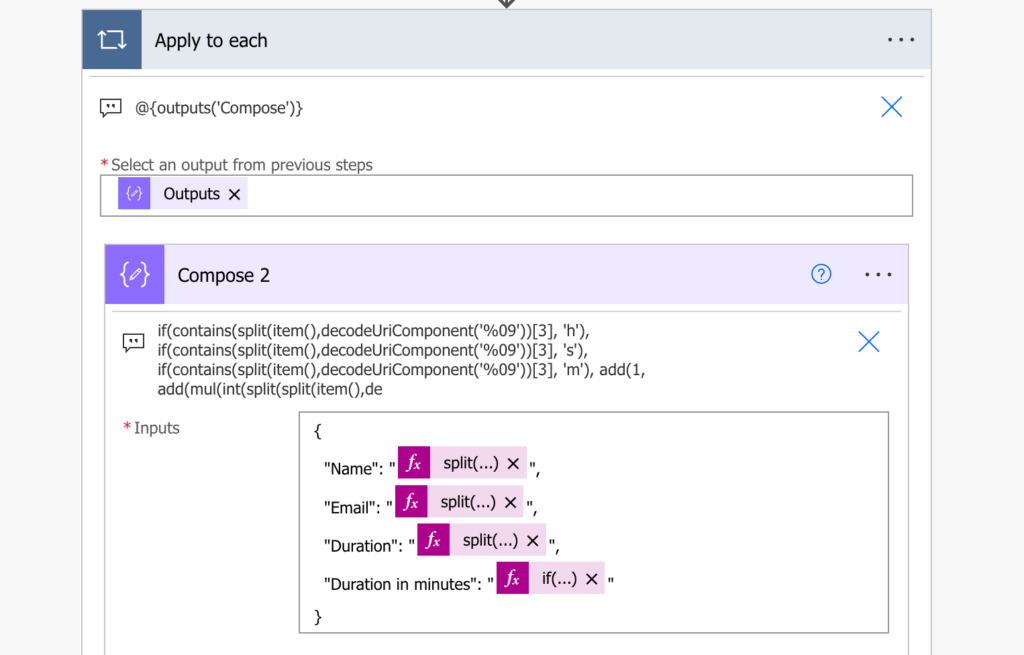
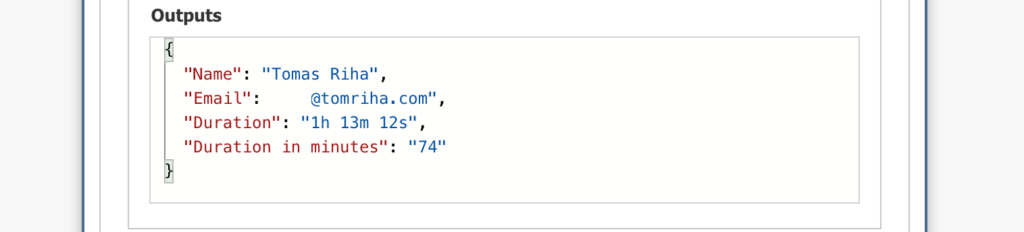
And the result is a number of minutes each user spent on the meeting.
Full flow diagram
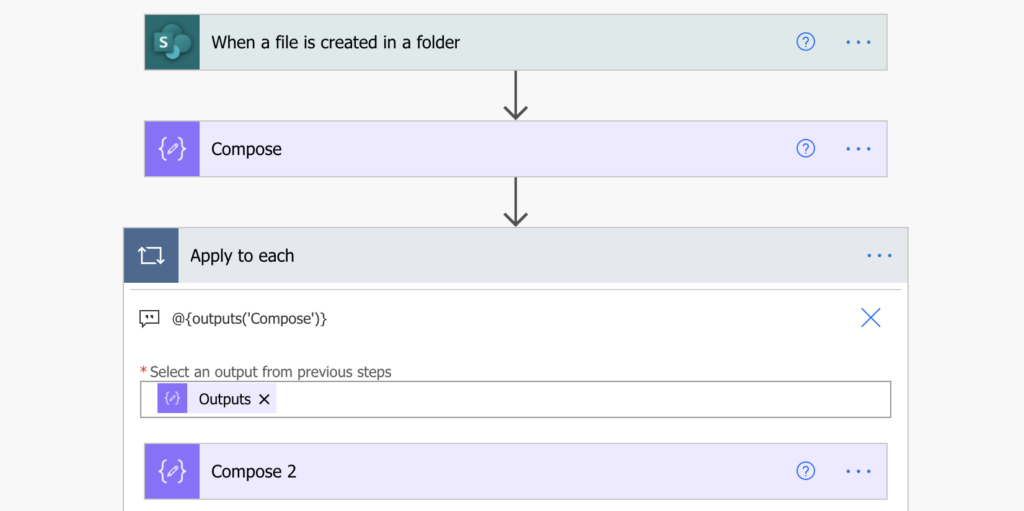
Summary
The Teams attendance report is a nice feature, although I wouldn’t call it ‘Power Automate friendly’. But with a few basic expressions, mostly the split(…) expression and indexing in the result array, you can extract the data for further processing. You can store the attendance data for each meeting separately, or aggregate it for each user in a SharePoint list for some long term summary. Or you can build further logic depending on the time spent on the meeting. Once you have the data you can process it in any way you like. All you need to do is to manually download the attendance report from Teams and upload it to a SharePoint library.
There’s also an option to extract the meeting attendance using Graph API, without the need of the .csv file as explained by Dennis in his article.
Hi,
Thanks for this, but I keep getting an error when I test it.
The error is:
Unable to process template language expressions in action ‘Compose_2’ inputs at line ‘0’ and column ‘0’: ‘The template language function ‘int’ was invoked with a parameter that is not valid. The value cannot be converted to the target type.’.
I have no idea what this means 🙂
Any advice would be appreciated, thanks.
Hello Matt,
there might be a problem if the attendance is shorter than 1 hour, you might need to use an extended expression in the ‘Compose 2’ action that’ll check if it should calculate with hours or only minutes:
if(contains(split(item(),decodeUriComponent('%09'))[3], 'h'),add(
mul(int(split(split(item(),decodeUriComponent('%09'))[3],'h ')[0]),60),
int(replace(split(split(item(),decodeUriComponent('%09'))[3],'h ')[1],'m',''))
),
if(contains(split(item(),decodeUriComponent('%09'))[3], 'm'),
add(
int(split(split(item(),decodeUriComponent('%09'))[3],'m ')[0]),
1
),
1
)
)
also I later found that the solution works only if you’re using Teams in English, the report changes the time format depending on local settings.
The input skip(split(triggerOutputs()?[‘body’],decodeUriComponent(‘%0A’)),8) returns the same code as output and it is being considered as a string in the future processes and not as an array.
Hello Nicy,
are you using the right dynamic content? Does the triggerOutputs()?[‘body’] contain any values? You can also try to split it by the other new line character ‘%0D%0A’ as described here: https://tomriha.com/how-to-replace-new-line-n-in-a-power-automate-expression/
Hi Tom,
Thank you so much for this tutorial, it is super helpful. I have two questions. The first is that I am getting the same error message as Matt. In my case, I have an attendance report that had three people attend. It pulls the information for the 3 people just fine, but it hangs up when it gets to the fourth row and there is no information to split. I’m not sure how to get it to stop after the rows containing only actual information.
Secondly, I would like to extract only the date from the Join column, as opposed to the date and time. I used the ‘%09’ as you recommended, which brought me to the value below:
“Date”: “4/26/2022, 10:57:36 AM”
From here, I would like to drop everything after the comma , but I am not sure how to do that. I think it requires a second split command, but I’m not sure what the command should look like.
Thanks again for any help you can provide!
Hello David,
I always add a ‘Condition’ to check if the current row is not empty to get rid of the empty lines.
Once you get the date you can use split() expression and take only the first part using index, as explained e.g. here: https://tomriha.com/how-to-split-file-name-for-further-processing-in-power-automate/
To get rid of everything after the comma you could use:,’,’)[0]
split(
Thank you so very much, Tom! I really appreciate it!
Hi,
How to get the Meeting Name and Meeting ID from the report.
Thanks.
Hello Prathima,
the Meeting Name is on the third row, and the Meeting Id is maybe the number on 6th row. Don’t use the skip(…), stop with the split() by the new line and select it using the index.
While the participants data is on columns, the summary part is on rows and I need to take only the Meeting title from that row. How can this be done? Thank you!
Hii,
Thank you for this information. I have one question should we not skip if we need general information as well, what will be the steps then?
Hello arsh,
if you need also the information on the first lines then don’t skip(…) anything, just split it by the new line character and process all the rows.
Hi Tom,
Thank you, this is great solution. The flow runs well but the apply to each seems to run twice and fails on the second run. This is the error received:
InvalidTemplate. Unable to process template language expressions in action ‘Compose_2’ inputs at line ‘0’ and column ‘0’: ‘The template language expression ‘split(item(),decodeUriComponent(‘%09′))[5]’ cannot be evaluated because array index ‘5’ is outside bounds (0, 0) of array.
Would you have any suggestions on how to get rid of this error?
Hello Malik,
as mentioned by Tyler below, the output was changed, you might try to modify the flow based on his explanation.
Thank you, Tom. I’ll give that a shot.
Hello Malik,
I just updated the article based on the new attendance reports and Tyler’s comment.
It seems like the outputs may have changed within the last year (or my organization is just different). We have 3 sections now on the attendance output and the number of lines before Participants is different.
1. Summary
2. Participants
3. In-Meeting activities
To address this I changed your first Compose to the following which gives only the participants list by splitting by two new line characters in a row:
skip(split(split(triggerOutputs()?[‘body’],decodeUriComponent(‘%0A%0A’))[1],decodeUriComponent(‘%0A’)),2)
Another difference that I found is that we have hours, minutes, and seconds listed in duration, and that it could be any combination of the three. To address this I modified the code you responded to Matt with to the following which does the following:
If hours
Yes If sec
Yes If min
Yes – Adds 1 min (for seconds) to the add (h*60, m)
No – Adds 1 min (for seconds) to the h*60
No If min
Yes – same as you posted
No – same as you posted
No If sec
Yes If min
Yes – Adds 1 min (for seconds) to the m calculation you posted
No – 1 min (for seconds)
No – same as you posted
And here is the code:
if(contains(split(item(),decodeUriComponent(‘%09’))[3], ‘h’),
if(contains(split(item(),decodeUriComponent(‘%09’))[3], ‘s’),
if(contains(split(item(),decodeUriComponent(‘%09’))[3], ‘m’),
add(1, add(mul(int(split(split(item(),decodeUriComponent(‘%09’))[3],’h ‘)[0]),60), int(split(split(split(item(),decodeUriComponent(‘%09’))[3],’h ‘)[1],’m ‘)[0]))),
add(1, mul(int(split(split(item(),decodeUriComponent(‘%09′))[3],’h’)[0]),60))
),
if(contains(split(item(),decodeUriComponent(‘%09’))[3], ‘m’),
add(mul(int(split(split(item(),decodeUriComponent(‘%09’))[3],’h ‘)[0]),60),int(replace(split(split(item(),decodeUriComponent(‘%09’))[3],’h ‘)[1],’m’,”))),
mul(int(split(split(item(),decodeUriComponent(‘%09’))[3],’h ‘)[0]),60)
)
),
if(contains(split(item(),decodeUriComponent(‘%09’))[3], ‘s’),
if(contains(split(item(),decodeUriComponent(‘%09’))[3], ‘m’),
add(1, int(split(split(item(),decodeUriComponent(‘%09′))[3],’m’)[0])),
1
),
int(split(split(item(),decodeUriComponent(‘%09′))[3],’m’)[0])
)
)
Hello Tyler,
thank you for sharing the solution, the attendance report was changed sometime during the summer (as I learned from a customer who’s using this solution >.<). I'll have to check if it was all the attendance reports or only the webinar attendance report and update the article.
I tried to come up with a smart way of splitting the attendance report after seeing that it had changed between July and August, but I couldn’t figure out how to drop the items that came after the In Meeting activities section, and so I was breaking my head on it.
Thank you very much for updating this. I still don’t think I follow the logic a 100%, and so I’m going to commit to really trying to grasp this material.
I have noticed the new “In Meeting activities section” — any ideas what this actually means? Nothing in the Microsoft documentation I can find.
Hello J B,
I have no idea, I guess it’ll show you if somebody left/joined/left etc. to give you more detailed information than just the summary.
At the first Compose, I’m receiving the following error:
Unable to process template language expressions in action ‘Compose’ inputs at line ‘0’ and column ‘0’: ‘The template language function ‘split’ expects its first parameter to be of type string. The provided value is of type ‘Object’.
I’ve double-checked my code to ensure it matches your code.
What am I missing?
Thanks for sharing your expertise.
Nevermind, it was because I was using an .xlsx file instead of a .csv file.
Why do I figure something out, *after* I post? 🙂
How would one take the Name, Email, Duration, etc. from the Compose 2 to add to a table in a spreadsheet?
The “Add a row into a table” I’ve configured doesn’t see the individual field results of Name, Email, Duration, etc.
Thank you!
I need more caffeine this morning. Here’s the solution:
Create multiple “Compose” elements that contain:
outputs(‘Compose_2’)[‘Name’]
outputs(‘Compose_2’)[‘First Joint’]
outputs(‘Compose_2’)[‘Last Leave’]
etc.
In my case I need to upload in SharePoint the csv file renamed in txt, because the original csv downloaded from Teams is in UTF-16 format….
Took me a good few hours to realise this same issue – file is downloaded as UTF16 by default from web or desktop Teams app. I solved it by inserting BOM in front of the content using this in a Compose:
concat(uriComponentToString(‘%EF%BB%BF’),body(‘Get_file_content_SP’))
Then I could apply the string manipulation….
skip(split(split(outputs(‘Compose’), ‘
‘)[1], decodeUriComponent(‘%0A’)), 2)
etc…
Weirdly, using the Get File content(Onedrive) can handle UTF16 but Get file content (Sharepoint) cannot. I needed to use SharePoint though.
What does ‘Get_file_content_SP’ refer to?
I am receiving a ‘The expression is invalid’ error
Hi,
complete noob here and not sure what I am doing wrong but trigger is working fine, however when I go one step further for Extract only the Participants section: split(triggerOutputs()?[‘body’],decodeUriComponent(‘%0A%0A’)) its giving me the same Output in form of the input split(triggerOutputs()?[‘body’],decodeUriComponent(‘%0A%0A’)), so essentially the same line is for input and output when I test it. What am I doing wrong?
Hello Asmir,
that happened to me when I modified the file, e.g. opened it in Excel and save it – it replaced the empty rows that this expression needs and added extra blank characters into the file = the expression stopped working. If you’re changing the file use a text editor.
this has been a great resource!!! we get both types of reports [old and new style] , typically based on permissions. can you post the old steps?
Hello Nicholas,
the old steps are long gone, not sure how to restore them without breaking the current article, but if I remember correctly the biggest difference was that the file didn’t have the sections before, the processing principles stay the same.
I have been successfully using this flow for the last two months and then out of no where without changing anything it failed today with the following error:
Unable to process template language expressions in action ‘Attendance_Compose’ inputs at line ‘0’ and column ‘0’: ‘The template language expression ‘skip(
split(
split(triggerOutputs()?[‘body’],decodeUriComponent(‘%0A%0A’))[1],
decodeUriComponent(‘%0A’)
),
2
)’ cannot be evaluated because array index ‘1’ is outside bounds (0, 0) of array.
Any idea what could have changed and why it is all of a sudden not working?
Hello Jennifer,
it happened to me before when somebody modified the file in Excel as Excel completely changes the empty characters in the file. If you need to edit the attendance file you must always use some plain text editor, e.g. notepad or visual studio code.
Hi Tom,
For regular monthly meeting, can the report aggregate for each month?
For example, below table will be added for each date per month onto the same Excel online file. The flow will just add on data the duration for each participant on the Excel. Let say last meeting is on 10-Aug. So we just upload the CSV file with name : Meet-10Aug.csv then the flow will extract duration data on column 10-Aug as below
10-Jun 20-Jul 10-Aug
Name 1 30m 40m 30m
Name 2 30m 30m 20m
Name 3 20m 10m 30m
…..
Name 12 25m 30m 20m
Hello Joe,
I believe it can, extract the attendance for each report and store in the Excel file. You have the email addresses in the reports so you can identify the Excel rows and then it’s only about filling the right column in the Excel, which I’d probably pre-create to have it ready for 12 months.
Hi Tom,
can you share how to extract meeting title, duration, no of attendees from 1st and name ,e mail and role from 2nd ? and I am getting outside bounds error even though file is not modified