“I’m spending a lot of time by copy/pasting information from email to SharePoint list, can I somehow automatically extract it with Power Automate?”
While there’re better ways to exchange information between various systems, email is probably one of the most straightforward ones. You send an email from one system to a specific email address, extract the information from the email body and store it somewhere else. Yet such approach can be quite time consuming if done manually, and not much fun to do. And maybe not needed at all if you can build a Power Automate flow to do that for you.
Start with the ‘HTML to text’ action
Always start with the ‘HTML to text’ action when processing emails. The full HTML code of the email can be quite confusing and this action will reduce it to a simple text. Let’s take for example an email I receive with every consulting request.
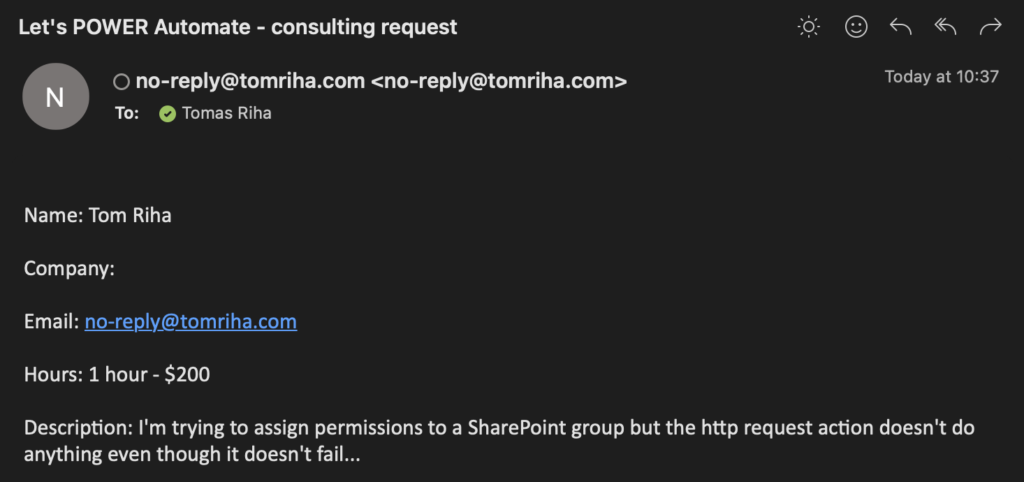
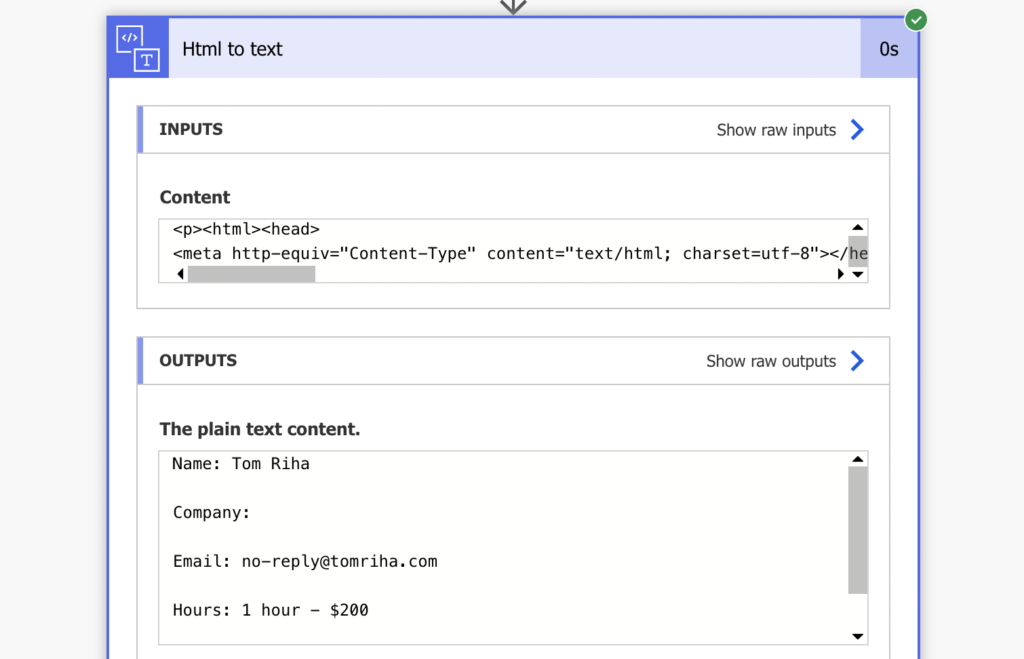
The ‘HTML to text’ action will take the whole email and remove all HTML tags to return the email content as a plain text.
Extract the information
Since it’s now a plain text, you can process it as any other string. As you can see on the screenshot above, the data in my email is separated by an empty line. That means the separator is one end of line character at the end of the line with text, and another end of line for the empty line. Therefore, I’ll split it by two end of line characters.
split(body('Html_to_text'),decodeUriComponent('%0A%0A'))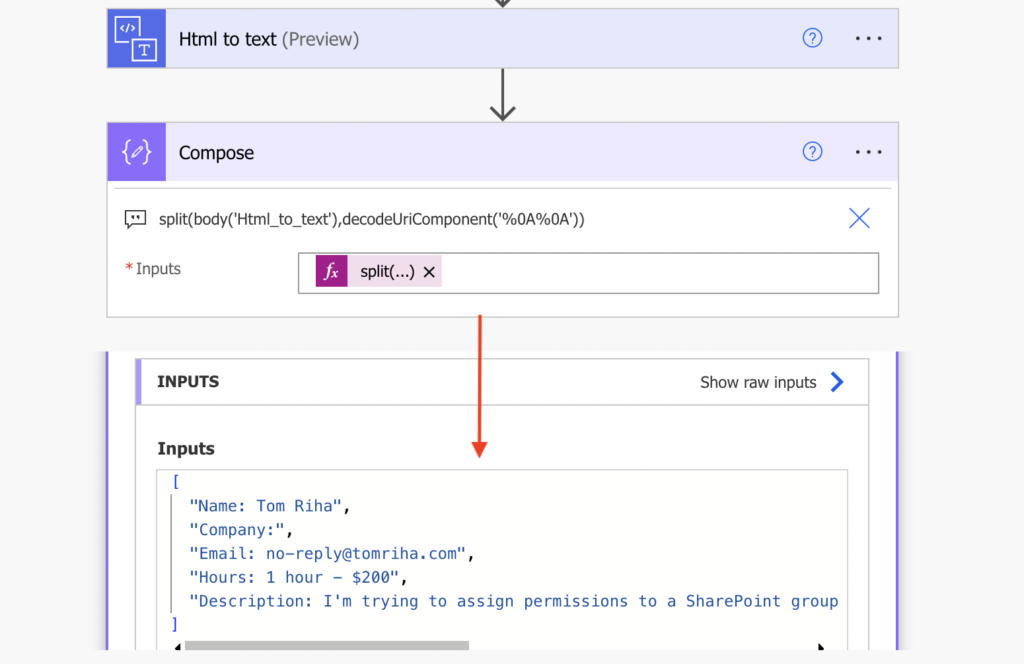
The result is a simple array with each line as a separate item. As with any other array I can now use indexes to pick specific line, e.g. 0 to get the name.
outputs('Compose')[0] -> Name: Tom RihaBut it’s still a bit more information than I need. I want to store just the name, without the ‘Name:’ description. Let’s do another split, this time on the ‘:’ character and take only the 2nd part, the name itself.
split(outputs('Compose')[0],':')[1] -> Tom RihaThe last step is to remove any potential spaces at the beginning or at the end of the name with the trim(…) function.
trim(split(outputs('Compose')[0],':')[1])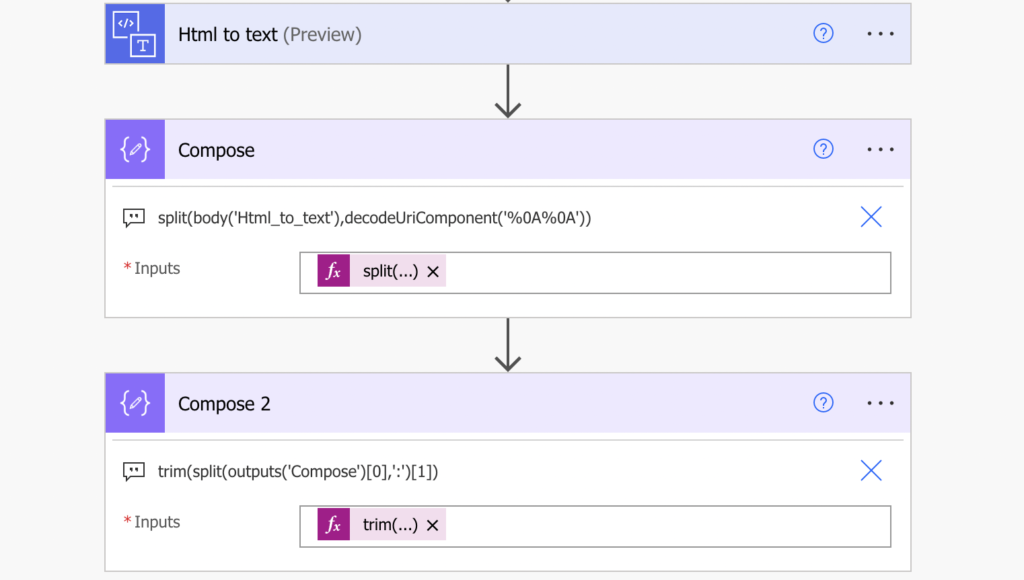
Following the same approach, just using different index numbers you can extract all the pieces of the email, one by one.
What if the information position can change?
Until now there was the expectation that the email has a fixed structure. But what if the positions can change? If the structured information is at the end of the email and you don’t know how much text is before?
It’s not a big deal as long as you have description for each of the lines. If it’s just the name, without the description ‘Name:’, you’re out of luck. There’s nothing to hold on. But if the name line starts with the ‘Name:’, you can use the ‘Filter array’ action instead of the index.
Use the parsed email as the input and filter only items that start with the description, in this case ‘Name:’.
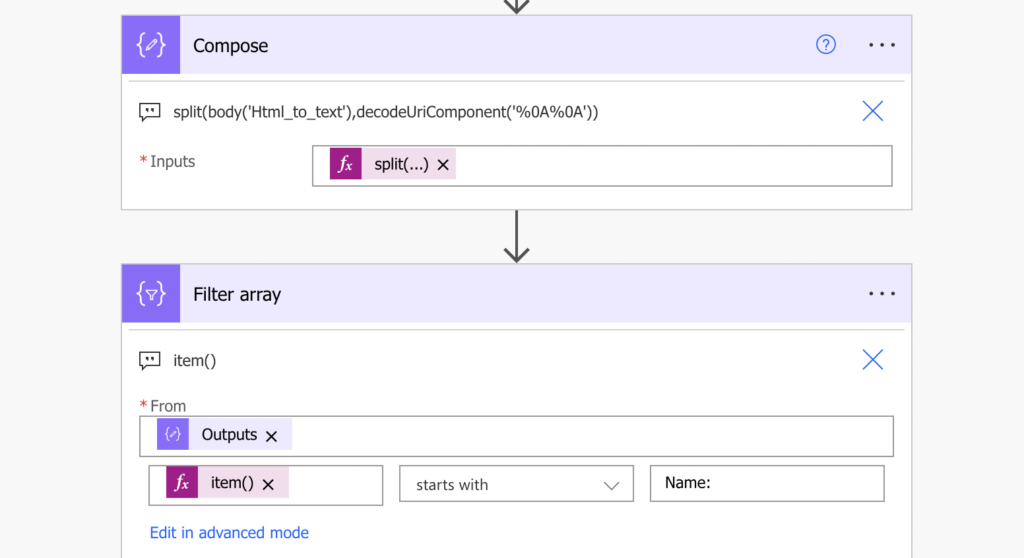
If the description is unique (and it should be unique), the ‘Filter array’ action will return just one line. Take it and process it as above – split by ‘:’ and trim(…) the spaces around it.
trim(split(body('Filter_array')[0],':')[1])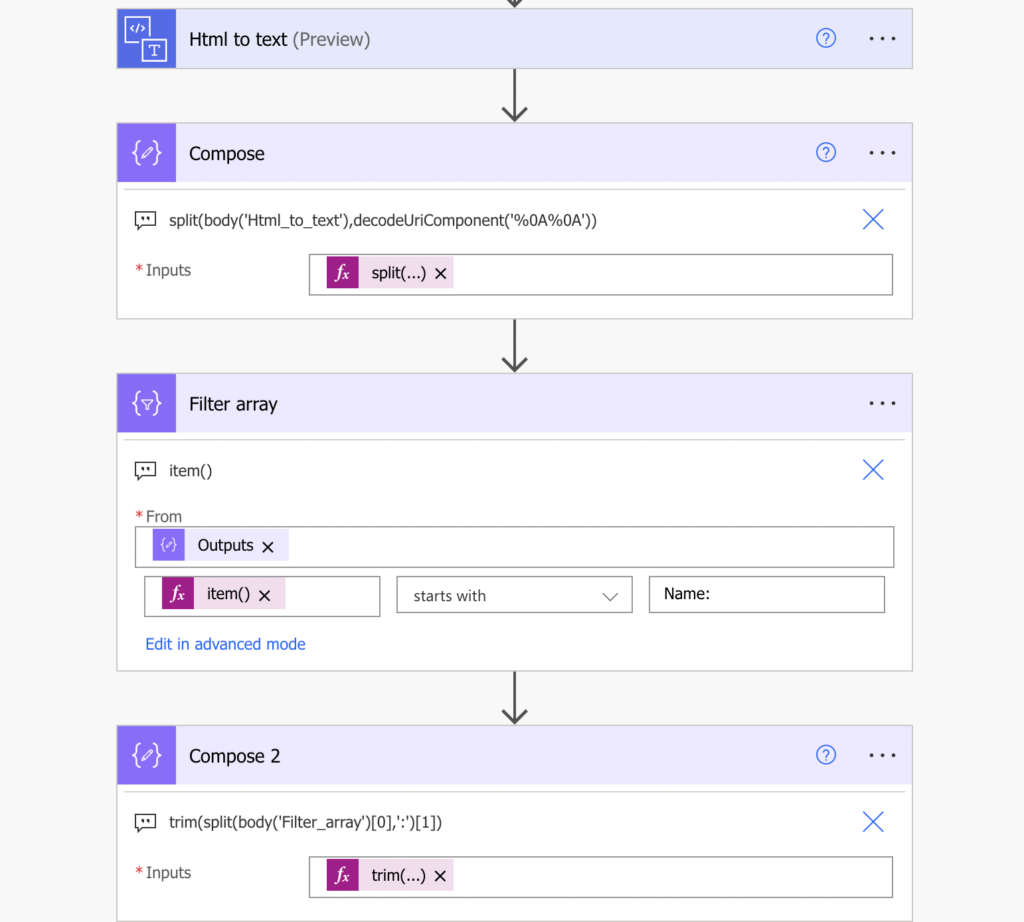
Repeat the same ‘Filter array’ to identify all the important lines, each looking for a different beginning of a line, and extract the data.
Summary
While this isn’t a complete guide on how to extract information from any email as each email is different, it should give you the basic idea how it’s done in Power Automate. It’s a lot of text processing. Get rid of the HTML tags, convert the email into plain text, and parse it. It can be many splits and many filters to get the desired information from complex emails (e.g. with tables or with information on different lines), but if you take it step by step you’ll get there (as long as there’s something to catch on).
Thank you for this great article on using split when it comes to extraction.
I find this useful but I’m looking for a way to extract the sender’s name when the email is coming from an outside account i.e., gmail or yahoo or similar.